

本文主要学习一下关于爬虫的相关前置知识和一些理论性的知识,通过本文我们能够知道什么是爬虫,都有那些分类,爬虫能干什么等,同时还会站在爬虫的角度复习一下http协议。
全套笔记和代码自取地址: 请移步这里
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
共 8 章,37 子模块
数据提取概要
本阶段本文主要学习响应之后如何从响应中提取我们想要的数据,在本阶段本文中我们会讲解一些常用的方法和模块,基本上我们以后遇到的情况在掌握本阶段本文之后都能搞定
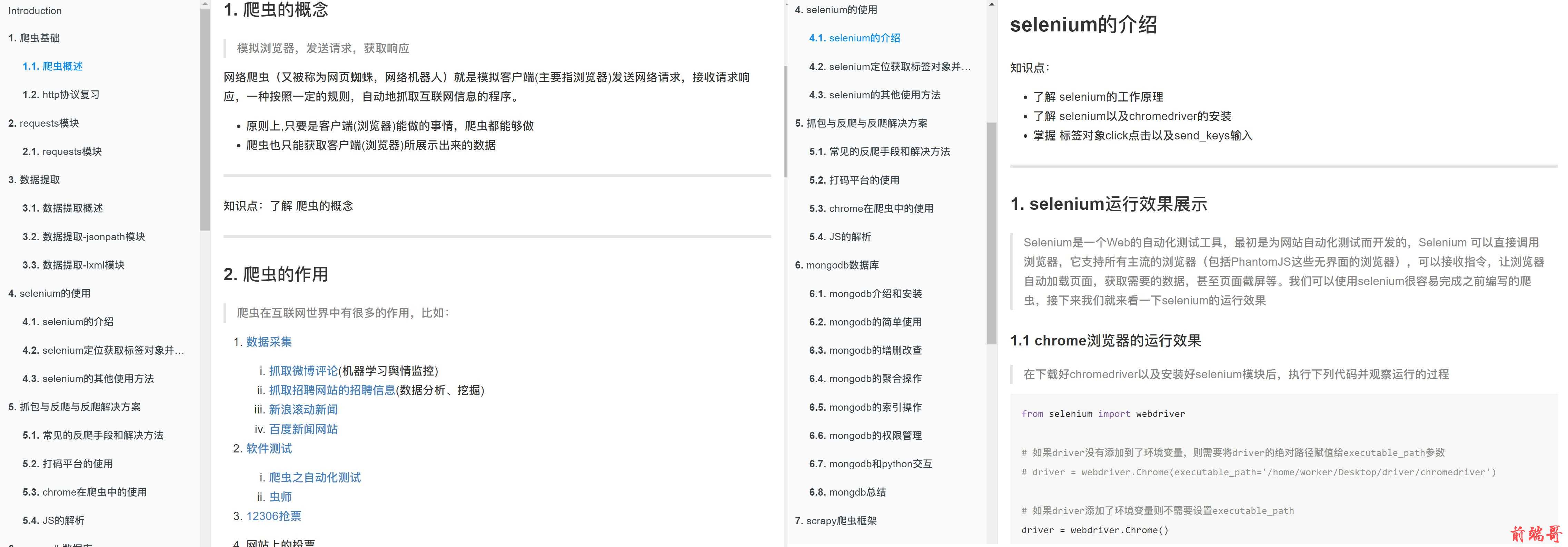
数据提取概述
知识点
- 了解 响应内容的分类
- 了解 xml和html的区别
1. 响应内容的分类
在发送请求响应之后,可能存在多种不同类型的响应内容;而且很多时候,我们只需要响应内容中的一部分数据
-
结构化的响应内容
-
json字符串
- 可以使用re、json等模块来提取特定数据
- json字符串的例子如下图

-
xml字符串
-
可以使用re、lxml等模块来提取特定数据
-
xml字符串的例子如下
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore> -
-
-
非结构化的响应内容
-
html字符串
- 可以使用re、lxml等模块来提取特定数据
- html字符串的例子如下图
-
知识点:了解 响应内容的分类
2. 认识xml以及和html的区别
要搞清楚html和xml的区别,首先需要我们来认识xml
2.1 认识xml
xml是一种可扩展标记语言,样子和html很像,功能更专注于对传输和存储数据
<bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
上面的xml内容可以表示为下面的树结构:

2.2 xml和html的区别
二者区别如下图
-
html:
- 超文本标记语言
- 为了更好的显示数据,侧重点是为了显示
-
xml:
- 可扩展标记语言
- 为了传输和存储数据,侧重点是在于数据内容本身
知识点:了解 xml和html的区别
2.3 常用数据解析方法

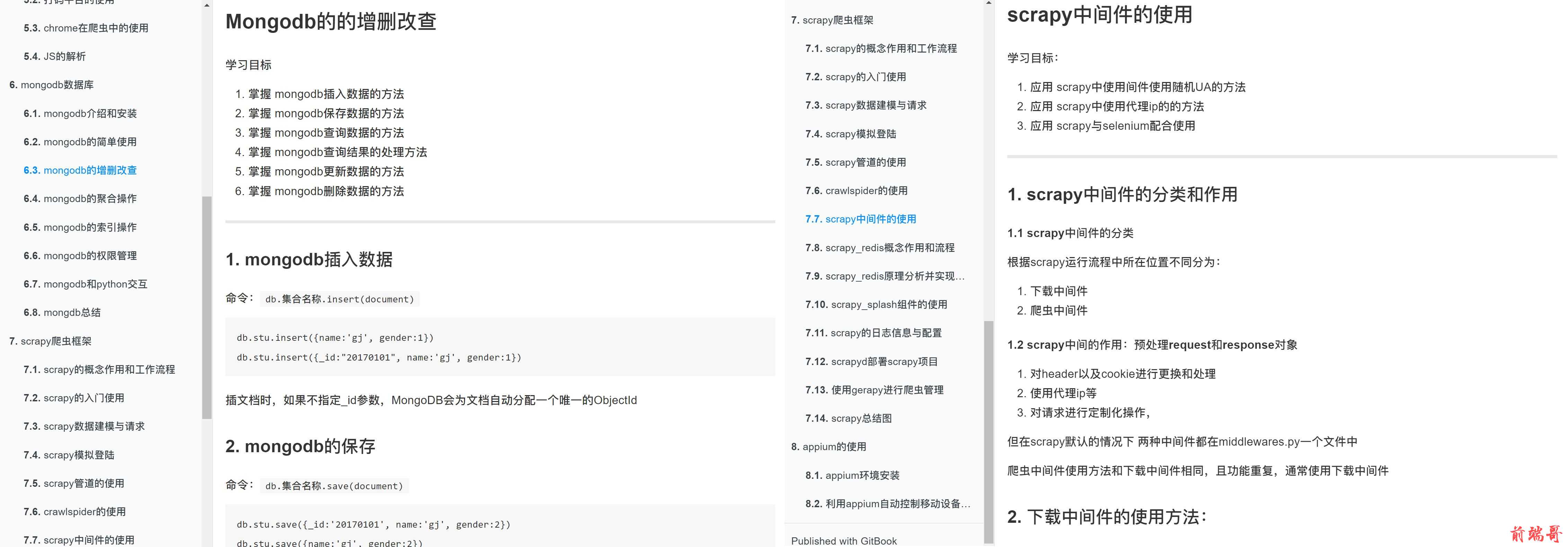
数据提取-jsonpath模块
知识点
- 了解 jsonpath模块的使用场景
- 掌握 jsonpath模块的使用
1. jsonpath模块的使用场景
如果有一个多层嵌套的复杂字典,想要根据key和下标来批量提取value,这是比较困难的。jsonpath模块就能解决这个痛点,接下来我们就来学习jsonpath模块
jsonpath可以按照key对python字典进行批量数据提取
知识点:了解 jsonpath模块的使用场景
2. jsonpath模块的使用方法
2.1 jsonpath模块的安装
jsonpath是第三方模块,需要额外安装
pip install jsonpath
2.2 jsonpath模块提取数据的方法
from jsonpath import jsonpath ret = jsonpath(a, 'jsonpath语法规则字符串')
2.3 jsonpath语法规则

2.4 jsonpath使用示例
book_dict = { "store": { "book": [ { "category": "reference", "author": "Nigel Rees", "title": "Sayings of the Century", "price": 8.95 }, { "category": "fiction", "author": "Evelyn Waugh", "title": "Sword of Honour", "price": 12.99 }, { "category": "fiction", "author": "Herman Melville", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "fiction", "author": "J. R. R. Tolkien", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } } } from jsonpath import jsonpath print(jsonpath(book_dict, '$..author')) # 如果取不到将返回False # 返回列表,如果取不到将返回False

3. jsonpath练习
我们以拉勾网城市JSON文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,所有城市的名字的列表,并写入文件。
参考代码:
import requests import jsonpath import json # 拉勾网城市json字符串 url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json' headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"} response =requests.get(url, headers=headers) html_str = response.content.decode() # 把json格式字符串转换成python对象 jsonobj = json.loads(html_str) # 从根节点开始,所有key为name的值 citylist = jsonpath.jsonpath(jsonobj,'$..name') # 写入文件 with open('city_name.txt','w') as f: content = json.dumps(citylist, ensure_ascii=False) f.write(content)

