背景介绍
LangChain提供了多种类型的Text Splitters,以满足不同的需求:
- RecursiveCharacterTextSplitter:基于字符将文本划分,从第一个字符开始。如果结果片段太大,则继续划分下一个字符。这种方式提供了定义划分字符和片段大小的灵活性。
- CharacterTextSplitter:类似于RecursiveCharacterTextSplitter,但能够指定自定义分隔符以实现更具体的划分。默认情况下,它尝试在如“\n\n”、“\n”和空格等字符上进行分割。
- RecursiveTextSplitter:与前两种类型不同,RecursiveTextSplitter基于单词或令牌而不是字符来划分文本。这种方法提供了更多的语义视角,使其成为内容分析的理想选择。
- TokenTextSplitter:利用OpenAI的语言模型基于令牌划分文本。这使得分割过程极其精确和具有上下文相关性,成为高级自然语言处理应用中不可或缺的工具。
安装依赖
| pip install -qU langchain-text-splitters |
HTML Splitter
编写代码
| from langchain_text_splitters import HTMLHeaderTextSplitter |
| |
| html_string = """ |
| <!DOCTYPE html> |
| <html> |
| <body> |
| <div> |
| <h1>Foo</h1> |
| <p>Some intro text about Foo.</p> |
| <div> |
| <h2>Bar main section</h2> |
| <p>Some intro text about Bar.</p> |
| <h3>Bar subsection 1</h3> |
| <p>Some text about the first subtopic of Bar.</p> |
| <h3>Bar subsection 2</h3> |
| <p>Some text about the second subtopic of Bar.</p> |
| </div> |
| <div> |
| <h2>Baz</h2> |
| <p>Some text about Baz</p> |
| </div> |
| <br> |
| <p>Some concluding text about Foo</p> |
| </div> |
| </body> |
| </html> |
| """ |
| |
| headers_to_split_on = [ |
| ("h1", "Header 1"), |
| ("h2", "Header 2"), |
| ("h3", "Header 3"), |
| ] |
| |
| html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on) |
| html_header_splits = html_splitter.split_text(html_string) |
| html_header_splits |
运行结果
| ➜ python3 test21.py |
| [Document(page_content='Foo'), Document(page_content='Some intro text about Foo. \nBar main section Bar subsection 1 Bar subsection 2', metadata={'Header 1': 'Foo'}), Document(page_content='Some intro text about Bar.', metadata={'Header 1': 'Foo', 'Header 2': 'Bar main section'}), Document(page_content='Some text about the first subtopic of Bar.', metadata={'Header 1': 'Foo', 'Header 2': 'Bar main section', 'Header 3': 'Bar subsection 1'}), Document(page_content='Some text about the second subtopic of Bar.', metadata={'Header 1': 'Foo', 'Header 2': 'Bar main section', 'Header 3': 'Bar subsection 2'}), Document(page_content='Baz', metadata={'Header 1': 'Foo'}), Document(page_content='Some text about Baz', metadata={'Header 1': 'Foo', 'Header 2': 'Baz'}), Document(page_content='Some concluding text about Foo', metadata={'Header 1': 'Foo'})] |
WebHTML Splitter
编写代码
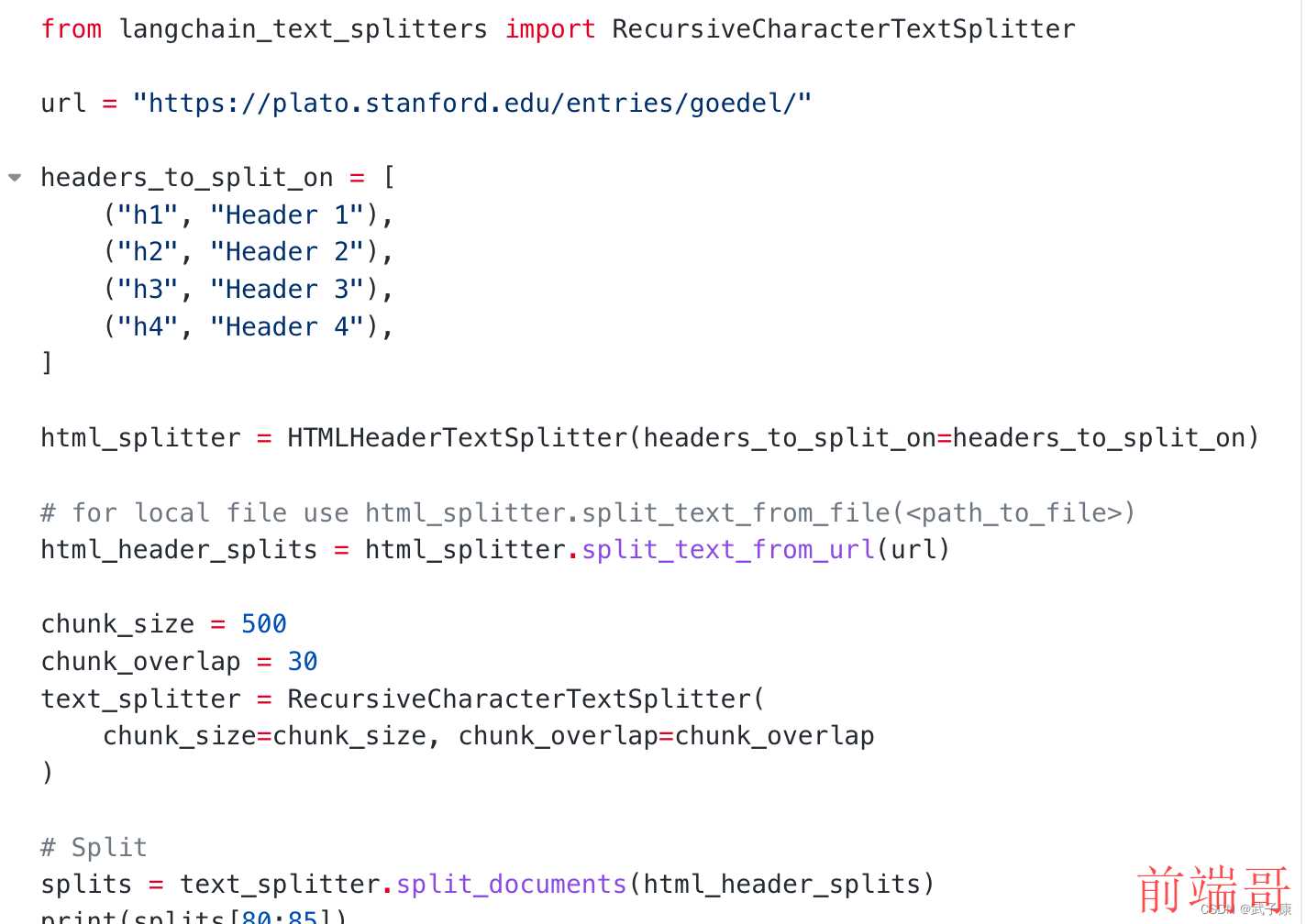
| from langchain_text_splitters import RecursiveCharacterTextSplitter |
| |
| url = "https://plato.stanford.edu/entries/goedel/" |
| |
| headers_to_split_on = [ |
| ("h1", "Header 1"), |
| ("h2", "Header 2"), |
| ("h3", "Header 3"), |
| ("h4", "Header 4"), |
| ] |
| |
| html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on) |
| |
| |
| html_header_splits = html_splitter.split_text_from_url(url) |
| |
| chunk_size = 500 |
| chunk_overlap = 30 |
| text_splitter = RecursiveCharacterTextSplitter( |
| chunk_size=chunk_size, chunk_overlap=chunk_overlap |
| ) |
| |
| |
| splits = text_splitter.split_documents(html_header_splits) |
| print(splits[80:85]) |
Character Splitter
编写代码
| from langchain_text_splitters import CharacterTextSplitter |
| |
| |
| with open("../../state_of_the_union.txt") as f: |
| state_of_the_union = f.read() |
| |
| text_splitter = CharacterTextSplitter( |
| separator="\n\n", |
| chunk_size=1000, |
| chunk_overlap=200, |
| length_function=len, |
| is_separator_regex=False, |
| ) |
| |
| texts = text_splitter.create_documents([state_of_the_union]) |
| print(texts[0]) |
Code Splitter
编写代码
| from langchain_text_splitters import ( |
| Language, |
| RecursiveCharacterTextSplitter, |
| ) |
| |
| |
| [e.value for e in Language] |
| |
| |
| RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON) |
Python Code Splitter
编写代码
| PYTHON_CODE = """ |
| def hello_world(): |
| print("Hello, World!") |
| |
| # Call the function |
| hello_world() |
| """ |
| python_splitter = RecursiveCharacterTextSplitter.from_language( |
| language=Language.PYTHON, chunk_size=50, chunk_overlap=0 |
| ) |
| python_docs = python_splitter.create_documents([PYTHON_CODE]) |
| print(python_docs) |
JavaScript Code Splitter
编写代码
| JS_CODE = """ |
| function helloWorld() { |
| console.log("Hello, World!"); |
| } |
| |
| // Call the function |
| helloWorld(); |
| """ |
| |
| js_splitter = RecursiveCharacterTextSplitter.from_language( |
| language=Language.JS, chunk_size=60, chunk_overlap=0 |
| ) |
| js_docs = js_splitter.create_documents([JS_CODE]) |
TypeScript Code Splitter
编写代码
| TS_CODE = """ |
| function helloWorld(): void { |
| console.log("Hello, World!"); |
| } |
| |
| // Call the function |
| helloWorld(); |
| """ |
| |
| ts_splitter = RecursiveCharacterTextSplitter.from_language( |
| language=Language.TS, chunk_size=60, chunk_overlap=0 |
| ) |
| ts_docs = ts_splitter.create_documents([TS_CODE]) |
| print(ts_docs) |
Markdown Splitter
编写代码
文本内容:
| markdown_text = """ |
| # 🦜️🔗 LangChain |
| |
| ⚡ Building applications with LLMs through composability ⚡ |
| |
| ## Quick Install |
| |
| ``bash |
| Hopefully this code block isn't split |
| pip install langchain |
| `` |
| |
| As an open-source project in a rapidly developing field, we are extremely open to contributions. |
| """ |
| |
代码解析:
| md_splitter = RecursiveCharacterTextSplitter.from_language( |
| language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0 |
| ) |
| md_docs = md_splitter.create_documents([markdown_text]) |
| print(md_docs) |
Markdown Header Splitter
编写代码
文本内容:
| # Foo\n\n ## Bar\n\nHi this is Jim \nHi this is Joe\n\n ## Baz\n\n Hi this is Molly |
代码解析:
| from langchain_text_splitters import MarkdownHeaderTextSplitter |
| |
| markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly" |
| |
| headers_to_split_on = [ |
| ("#", "Header 1"), |
| ("##", "Header 2"), |
| ("###", "Header 3"), |
| ] |
| |
| markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on) |
| md_header_splits = markdown_splitter.split_text(markdown_document) |
| print(md_header_splits) |
JSON Splitter
| import json |
| import requests |
| from langchain_text_splitters import RecursiveJsonSplitter |
| |
| |
| json_data = requests.get("https://api.smith.langchain.com/openapi.json").json() |
| splitter = RecursiveJsonSplitter(max_chunk_size=300) |
| |
| json_chunks = splitter.split_json(json_data=json_data) |
| |
| docs = splitter.create_documents(texts=[json_data]) |
| |
| |
| texts = splitter.split_text(json_data=json_data) |
| |
| print(texts[0]) |
| print(texts[1]) |


