
一、代码块目录详情
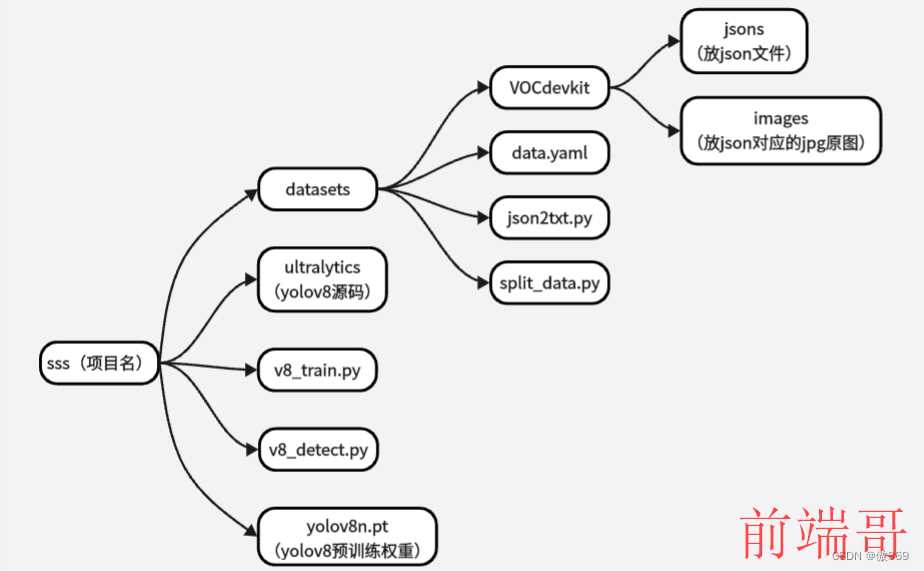
二、json2txt.py
import json import os def convert_annotation(json_file, txt_file, label_to_id_mapping): # Read the JSON file with open(json_file, 'r', encoding='utf-8') as f: data = json.load(f) # Extract image dimensions, assuming 'imageWidth' and 'imageHeight' fields are present image_width = data.get('imageWidth') image_height = data.get('imageHeight') # Check if image dimensions are present if image_width is None or image_height is None: raise ValueError(f"Missing image dimensions in {json_file}") # Iterate over all shapes (annotations) with open(txt_file, 'w', encoding='utf-8') as out_file: for shape in data.get('shapes', []): # Extract point coordinates, assuming each shape has a 'points' field points = shape.get('points', []) # Check if points are present if not points: raise ValueError(f"Missing points in a shape in {json_file}") x_values = [point[0] for point in points] y_values = [point[1] for point in points] x_min = min(x_values) y_min = min(y_values) x_max = max(x_values) y_max = max(y_values) # Calculate bounding box center, width, and height bbox_center_x = (x_min + x_max) / 2 bbox_center_y = (y_min + y_max) / 2 bbox_width = x_max - x_min bbox_height = y_max - y_min # Convert bounding box coordinates to ratios relative to image dimensions bbox_center_x_ratio = bbox_center_x / image_width bbox_center_y_ratio = bbox_center_y / image_height bbox_width_ratio = bbox_width / image_width bbox_height_ratio = bbox_height / image_height # Get the category ID, assuming each shape has a 'label' field category_id = shape.get('label', "unknown") if isinstance(category_id, str): # If the label is a string, map it to a numeric ID using the provided mapping category_id = label_to_id_mapping.get(category_id, -1) # Default to -1 if label is unknown # Write the result to the TXT file in YOLO format out_file.write( f"{int(category_id)} {bbox_center_x_ratio} {bbox_center_y_ratio} {bbox_width_ratio} {bbox_height_ratio}\n") # Input and output folder paths input_folder = 'D:/sss/datasets/VOCdevkit/jsons' output_folder = 'D:/sss/datasets/VOCdevkit/txt' os.makedirs(output_folder, exist_ok=True) # 标注物体的类别名 label_to_id_mapping = { 'Red Light': 0, 'Red Light': 1, 'Yellow Light': 2 # Add more mappings as needed } # Iterate over all JSON files in the input folder for filename in os.listdir(input_folder): if filename.endswith('.json'): json_file = os.path.join(input_folder, filename) txt_file = os.path.join(output_folder, filename.replace('.json', '.txt')) try: convert_annotation(json_file, txt_file, label_to_id_mapping) print(f'{txt_file},Conversion successful!') except Exception as e: print(f"An error occurred while processing {json_file}: {e}")
三、split_data.py
import os, shutil from sklearn.model_selection import train_test_split val_size = 0.1 test_size = 0.1 postfix = 'jpg' imgpath = 'VOCdevkit/images' txtpath = 'VOCdevkit/txt' os.makedirs('images/train', exist_ok=True) os.makedirs('images/val', exist_ok=True) os.makedirs('images/test', exist_ok=True) os.makedirs('labels/train', exist_ok=True) os.makedirs('labels/val', exist_ok=True) os.makedirs('labels/test', exist_ok=True) listdir = [i for i in os.listdir(txtpath) if 'txt' in i] train, test = train_test_split(listdir, test_size=test_size, shuffle=True, random_state=0) train, val = train_test_split(train, test_size=val_size, shuffle=True, random_state=0) print(f'train set size:{len(train)} val set size:{len(val)} test set size:{len(test)}') for i in train: shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'images/train/{}.{}'.format(i[:-4], postfix)) shutil.copy('{}/{}'.format(txtpath, i), 'labels/train/{}'.format(i)) for i in val: shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'images/val/{}.{}'.format(i[:-4], postfix)) shutil.copy('{}/{}'.format(txtpath, i), 'labels/val/{}'.format(i)) for i in test: shutil.copy('{}/{}.{}'.format(imgpath, i[:-4], postfix), 'images/test/{}.{}'.format(i[:-4], postfix)) shutil.copy('{}/{}'.format(txtpath, i), 'labels/test/{}'.format(i))
四、data.yaml
# 划分数据集的地址 train: D:\sss\datasets\images\train val: D:\sss\datasets\images\val test: D:\sss\datasets\images\test # 标注的类别数量 nc: 3 # 类别名称 names: ['Red Light', 'Red Light', 'Yellow Light']
兄台,本章对你有用的话,记得一键三连哦!
更多资源,请移步至本人的github首页:lcx9451 (lcx9451) (github.com)

